Мой AI SRE запорожец


AI (LLM, я больше такое люблю название, но везде будет AI) используется повсеместно, в том числе и тем более девопсами. Манифест сгенерить или целый хельм, разобраться в инциденте — это вот всё. Даже пост-мортем собрать, это тоже отличное использование. Но что насчет полной автономии? Это вообще возможно?
На рынке представлено немного решений и как обычно это бывает, придется собирать из кусочков OpenSource какое-то цельное решение.
Я опишу то, что мне было интересно сделать самому. Правда пришлось даже поконтрибютить самому: это в платных решениях можно за свои деньги поныть и получить патч, а в бесплатном решении свои и заодно чужие проблемы решаешь сам.
На момент реализации из всех решений, известных мне, свободно и бесплатно для использования я нашел только KeepHQ. Неплохой дашик с алертами, в который натолкали вообще все, что можно было натолкать, десятки интеграций со всем, чем только можно.
Но мало иметь интеграции, нужна управляемость. И тут, как у многих, развилка: либо лицензия с полным функционалом, либо бесплатно с рядом ограничений (что лучше ещё спорно, я лицензию не пробовал). Авторизация из той же серии: теоретически KeepHQ умеет всё из коробки, а на практике бесплатно доступно либо вообще без авторизации, либо через OAuth-прокси, который умеет в SSO.
Итак, дашборд с алертами, SSO и даже дедупликацией — это каркас. Но это всё ещё просто красивый список инцидентов. Где же тот самый AI, который сам сходит и разберётся? Сам Keep сюда AI не приносит, его нужно подключить отдельным движком.
Кое-какие базовые штуки он, правда, может и сам, для вау-эффекта. Например, чатик в инциденте, где ты можешь спросить, а что собственно происходит, и пианист сыграет как сумеет.
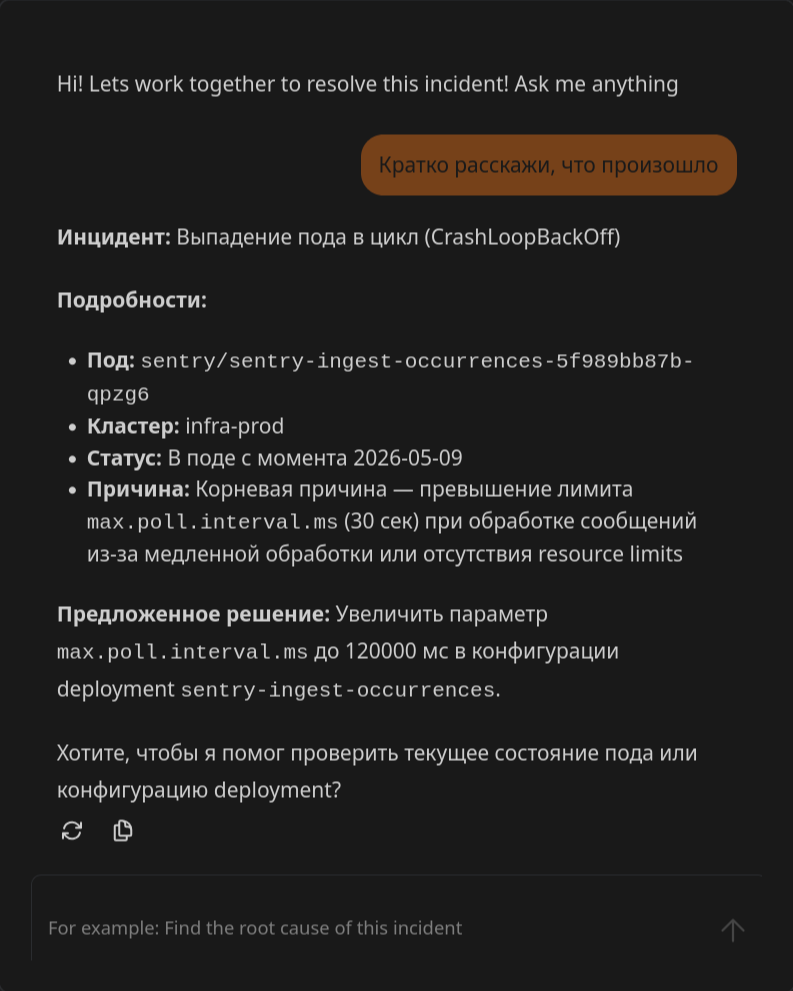
В целом у меня получилось два способа получения информации от LLM. Первый — это чат в инциденте, где вы можете просто получить общую информацию и пообщаться с роботом. Это неплохо например для сторонних менеджеров, которые просто хотят понять, что именно сломано. Но чат этот хранится на фронтенде в рантайме непосредственно сессии и не шерится между пользователями, что кстати постоянно приводит к переполнению localStorage браузера и полному падению сессии без возможности открытия Keep. Приходится чистить cookies. В общем, игрушка на первое время, чат не особо помогает, когда по инциденту и так всё понятно.
Второй способ, он же основной, это именно дедупликация алертов, формирование инцидента и первичное проведение расследования. Вот тут одним Keep не обойтись, придется к своему корпусу прикручивать двигатель. Но прежде чем прикручивать, давай разберёмся, как из кучи алертов вообще получается один инцидент — это Keep умеет сам, без всякого AI.
За склейку отвечает правило корреляции. По сути это ответ на три вопроса: какие алерты я вообще беру, по какому признаку их слепляю вместе и за какой промежуток времени. Первое — это фильтр, и задаётся он на CEL (Common Expression Language). Можно написать что-то умное вроде «только critical с определённого сервиса», а можно — как у меня — `source != null`, то есть «бери вообще всё, у чего есть источник». Второе — ключ группировки: я слепляю по имени алерта, так что все срабатывания с одинаковым именем падают в один инцидент. Третье — окно: сутки. Всё, что прилетело в пределах суток под тем же именем, считается тем же инцидентом, а не плодит десять новых.
Дальше пара галочек, которые и делают это автономным. Инцидент создаётся на первом же подходящем алерте — не ждём, пока накопится пять. Закрывается сам, когда все входящие в него алерты потухли (именно все, а не любой из них — на этом я сначала обжёгся). И никакого ручного подтверждения: правило само открывает инцидент, без человека.
# Keep correlation rule — как алерты склеиваются в инцидент
name: Group by Alert Name
filter: "source != null" # CEL: берём любой алерт с источником (фактически все)
group_by:
- name # одинаковое имя алерта → один инцидент
timeframe: 24h # скользящее окно склейки
create_on: any # открыть инцидент на первом же совпавшем алерте
resolve_on: all_resolved # закрыть сам, когда все алерты внутри потухли
incident_name: "{{ name }}" # имя инцидента = имя алерта
require_approve: false # полностью автоматически, без подтверждения
Звучит примитивно — группировка по имени, и всё. Но даже такая склейка уже убирает основную боль: вместо пятнадцати одинаковых писем про упавшую ноду ты видишь один инцидент. Хочешь умнее — группируй по хосту, сервису, лейблам, городи многоуровневые правила. Мне хватило простого. А главное — именно рождение этого инцидента и есть тот спусковой крючок, по которому дальше заводится вся остальная машинерия.
А машинерии набегает прилично, поэтому, чтобы дальше не потеряться в том, кто кого дёргает, вот вся схема одним куском. Ниже разберу каждый кусок по отдельности, но общая картина такая:
Alertmanager ──webhook──▶ Keep ──correlation rule──▶ Incident
(VMAlert) (alerts) group_by: name, │ "incident.created"
window 24h │
▼
┌──────────────────────────┐
│ Keep Workflow │
│ 1. title ──▶ LLM (cheap)│
│ 2. investigate ──▶ Holmes │
│ 3. summary ──▶ LLM (cheap)│
│ 4. update incident │
│ 5. add comment │
└─────────┬──────────────────┘
│ /api/chat
▼
┌──────────────────────────┐
│ HolmesGPT │
│ agent + runbooks │──▶ LLM (heavy)
└─────────┬──────────────────┘
│ MCP over SSE
┌─────────────┴─────────────┐
▼ ▼
mcp-victoriametrics mcp-victorialogs
│ │
▼ ▼
VictoriaMetrics VictoriaLogs
(PromQL / метрики) (LogsQL / логи)
Готовый анализ Holmes ──▶ шаги 4-5 воркфлоу ──▶ в инциденте появляются
заголовок, выжимка и комментарий ──▶ всё это видит инженер в Keep
Keep тут диспетчер, воркфлоу — оркестратор, Holmes — мозг, MCP — руки к данным, а две LLM-модели (дешёвая и тяжёлая) стоят там, где каждая уместна. А теперь по порядку.
Движок, который я взял — HolmesGPT. Это open-source AI-агент для расследования инцидентов, и делает его компания Robusta. Нюанс в том, что у Robusta есть и своя платформа, полноценный SaaS-продукт, за деньги. Но само ядро, HolmesGPT, лежит в открытом доступе и спокойно запускается отдельно. То есть вендор отдаёт мотор бесплатно, а платную платформу строит сверху. Мне платная платформа не нужна, мне нужен мотор. Весь смысл этой статьи ровно в этом: взять открытое ядро и собрать вокруг него автономную обвязку самому, ничего не занося в кассу.
Ключевая разница с обычным «скорми алерт в Claude» — это то, что Holmes не пересказывает текст алерта. Это агент с инструментами: ему дают доступ к источникам данных, и он сам решает, куда сходить. Прилетел инцидент, он сам идёт в метрики, сам смотрит логи за нужный промежуток, сам сопоставляет и пишет, что, по его мнению, произошло и где копать. Человек открывает инцидент и видит уже не голый алерт, а собранную картину. Решение и действия остаются за инженером (никакого auto-remediation, и это сознательно), но самую нудную часть, а именно сбор контекста, агент снимает.
Доступ к данным Holmes получает через MCP. Я поднял два MCP-сервера: один к метрикам (VictoriaMetrics), другой к логам (VictoriaLogs), оба по SSE. Дальше агент сам гоняет по ним запросы — PromQL по метрикам, LogsQL по логам.
Вот пример простейшего манифеста запуска MCP для Виктории. Кстати, эта штука может пригодиться и инженеру на работе, если он подключит их в собственные AI-инструменты.
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: mcp-victoriametrics
namespace: monitoring
spec:
replicas: 1
selector:
matchLabels:
app: mcp-victoriametrics
template:
metadata:
labels:
app: mcp-victoriametrics
spec:
containers:
- name: mcp-victoriametrics
image: ghcr.io/victoriametrics/mcp-victoriametrics:latest
env:
- name: VM_INSTANCE_ENTRYPOINT
value: "http://vmselect-victoria-metrics-k8s-stack.monitoring.svc:8481"
- name: VM_INSTANCE_TYPE
value: "cluster"
- name: MCP_SERVER_MODE
value: "sse"
- name: MCP_LISTEN_ADDR
value: ":8080"
ports:
- containerPort: 8080
resources:
requests:
cpu: 100m
memory: 128Mi
limits:
cpu: "2"
memory: 6Gi
---
apiVersion: v1
kind: Service
metadata:
name: mcp-victoriametrics
namespace: monitoring
spec:
selector:
app: mcp-victoriametrics
ports:
- port: 8080
targetPort: 8080
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: mcp-victorialogs
namespace: monitoring
spec:
replicas: 1
selector:
matchLabels:
app: mcp-victorialogs
template:
metadata:
labels:
app: mcp-victorialogs
spec:
containers:
- name: mcp-victorialogs
image: ghcr.io/victoriametrics-community/mcp-victorialogs:latest
env:
- name: VL_INSTANCE_ENTRYPOINT
value: "http://victoria-logs-cluster-vlselect.victoria-logs-cluster.svc:9471"
- name: MCP_SERVER_MODE
value: "sse"
- name: MCP_LISTEN_ADDR
value: ":8080"
ports:
- containerPort: 8080
resources:
requests:
cpu: 100m
memory: 128Mi
limits:
cpu: "2"
memory: 6Gi
---
apiVersion: v1
kind: Service
metadata:
name: mcp-victorialogs
namespace: monitoring
spec:
selector:
app: mcp-victorialogs
ports:
- port: 8080
targetPort: 8080
А подключается всё это к HolmesGPT прямо в Helm, из коробки:
mcp_servers:
victoriametrics:
description: "VictoriaMetrics — query metrics with PromQL/MetricsQL, explore labels, check alerts and rules, analyze cardinality"
config:
url: "http://mcp-victoriametrics.monitoring.svc.cluster.local:8080/sse"
mode: sse
victorialogs:
description: "VictoriaLogs — search logs with LogsQL, explore streams and fields, query log statistics"
config:
url: "http://mcp-victorialogs.monitoring.svc.cluster.local:8080/sse"
mode: sse
Теперь, когда у Holmes есть доступ к данным, интересно посмотреть, как он этими данными распоряжается. А распоряжается он на удивление по-человечески: не бросается сразу дёргать команды, сначала составляет план. Буквально заводит себе todo-лист и бьёт расследование на фазы — сперва разберись с таймлайном алерта, потом найди нужные метрики и логи, потом выдвини гипотезу и проверь её, и только в конце сведи всё вместе и сформулируй причину. И дальше идёт по этому списку, отмечая шаги сделанными. Прямо как нормальный инженер, который не тычется во всё подряд, а сначала прикидывает, с чего начать. Первым делом, кстати, он подтягивает ту самую методичку про расследование (а вы писали ранбуки для своих инженеров? Если да, то они бы тут пригодились) — и уже по ней раскладывает фазы.

Про методички стоит сказать отдельно. Скиллы для использования Victoria-стека тоже могут быть полезны, но имейте в виду, что они написаны в первую очередь для локального подключения, это может немного путать AI. Дело в том, что там в скиллах явно прописаны переменные окружения, которые должны быть заданы. И тут можно попробовать положить их на init-контейнере (так себе идея) или переделать под себя. Однако я использовал дефолтные:
initContainers:
- name: download-skills
image: alpine/git:latest
command:
- sh
- -c
- |
set -e
git clone --depth=1 https://github.com/VictoriaMetrics/skills.git /tmp/skills
mkdir -p /runbooks
cp /tmp/skills/plugins/query/skills/victoriametrics-query/SKILL.md /runbooks/victoriametrics-query.md
cp /tmp/skills/plugins/query/skills/victorialogs-query/SKILL.md /runbooks/victorialogs-query.md
cp /tmp/skills/plugins/query/skills/alertmanager-query/SKILL.md /runbooks/alertmanager-query.md
cp /tmp/skills/plugins/diagnostics/skills/investigating-with-observability/SKILL.md /runbooks/investigating-with-observability.md
cp /tmp/skills/plugins/diagnostics/skills/victoriametrics-cardinality-analysis/SKILL.md /runbooks/victoriametrics-cardinality-analysis.md
cat > /runbooks/catalog.json << 'EOF'
{"catalog": [
{"id": "victoriametrics-query", "update_date": "2026-03-18", "description": "Query metrics with PromQL/MetricsQL, discover metrics and labels, check firing alerts and rules.", "link": "victoriametrics-query.md"},
{"id": "victorialogs-query", "update_date": "2026-03-18", "description": "Search logs with LogsQL, run stats queries, discover fields and streams, analyze log volume.", "link": "victorialogs-query.md"},
{"id": "alertmanager-query", "update_date": "2026-03-18", "description": "List active and silenced alerts, check alert inhibition state.", "link": "alertmanager-query.md"},
{"id": "investigating-with-observability", "update_date": "2026-03-18", "description": "Multi-signal investigation across metrics, logs, and traces with structured phases.", "link": "investigating-with-observability.md"},
{"id": "victoriametrics-cardinality-analysis", "update_date": "2026-03-18", "description": "Analyze time series cardinality to find optimization opportunities.", "link": "victoriametrics-cardinality-analysis.md"}
]}
EOF
volumeMounts:
- name: skills
mountPath: /runbooks
Обратите внимание, что я по сути переписал runbooks-папку. И это сделано сознательно, потому что я отдаю AI-инструменту только те скиллы и инструменты, которые считаю необходимыми. Я попросил его делать выводы только на основе метрик и логов (так же можно подключить и трейсы, если конечно они у вас есть).
Да, и kubectl я тоже запретил — а он встроен в HolmesGPT из коробки. Но в моём случае кластеров много, и разрешать агенту ходить по ним я не вижу необходимости, когда есть общий коллектор для мониторинга. Для всего остального есть инженер.
Раз уж агент умеет в bash, его надо держать в узде. Здесь allowlist по префиксам: разрешены curl, jq, wget и ещё горстка, всё остальное требует явного подтверждения. Так агент может дёрнуть HTTP-API руками, когда надо, но не наломает дров.
toolsets:
bash:
enabled: true
config:
builtin_allowlist: extended
allow:
- curl
- jq
- wget
kubernetes/core: { enabled: false } # kubectl выключен сознательно
kubernetes/logs: { enabled: false }
prometheus/metrics: { enabled: false } # метрики не через прометей, а через MCP VictoriaMetrics
Окей, движок есть, данные есть, ограничения расставлены. Holmes умеет в расследование. Но проблема в том, что сам по себе он ничего не делает. Это эндпоинт: дёрнул — ответил, не дёрнул — лежит. А мне нужно, чтобы он включался сам на каждый инцидент, без меня. Для этого я использую движок воркфлоу самого Keep.
Триггер у меня один и максимально тупой: инцидент создан. Keep сам коррелирует кучу алертов в один инцидент (как — я разобрал выше), и в момент, когда инцидент рождается, дёргается мой воркфлоу. Дальше пять шагов, по порядку. А вот и сам воркфлоу:
workflow:
id: holmes-investigate-incident
name: Holmes Investigate Incident
description: Deep investigation when an incident is created
triggers:
- type: incident
events:
- created
steps:
# 1) Short, human-readable title from the alerts (cheap model, no tools).
- name: generate-title
provider:
type: http
with:
url: http://llm-gateway:4000/v1/chat/completions
method: POST
headers:
Content-Type: application/json
body:
model: your-small-model
max_tokens: 50
messages:
- role: system
content: "You generate short incident titles, 2-5 words. Describe ONLY the type of problem, NOT specific servers or hosts. Examples: Disk filling up, NVMe errors, High CPU load, Service unavailable. Output ONLY the title, nothing else. No quotes, no markdown."
- role: user
content: "Alerts in incident - {{#incident.alerts}}{{name}}: {{description}}; {{/incident.alerts}} Generate a title."
# 2) The actual investigation. Holmes pulls metrics and logs itself and returns an analysis.
- name: investigate
provider:
type: http
with:
url: http://holmes:5050/api/chat
method: POST
body:
ask: "Incident: {{ incident.name }}. Alerts: {{ incident.alerts_count }}. {{#incident.alerts}}{{name}}: {{description}}; {{/incident.alerts}}"
additional_system_prompt: "Output plain text only, no markdown, no headings, no bullet lists, write in continuous prose. CRITICAL: NEVER ask clarifying questions, you are an automated agent with no human in the loop. NEVER use kubectl or any Kubernetes CLI tools, they connect to the wrong cluster and return misleading data. Use ONLY the metrics MCP for metrics, the logs MCP for logs, and bash with curl for HTTP APIs. All Kubernetes information is available through metrics like kube_pod_status_phase, kube_node_status_condition, kube_daemonset_status_desired_number_scheduled etc. Query those instead of kubectl. Always produce a concrete analysis with root cause and remediation, even if partial."
on-failure:
retry:
count: 5
interval: 30
# 3) One- to two-sentence summary of the analysis (cheap model again).
- name: generate-summary
if: "'{{ steps.investigate.results.status_code }}' == '200'"
provider:
type: http
with:
url: http://llm-gateway:4000/v1/chat/completions
method: POST
headers:
Content-Type: application/json
body:
model: your-small-model
max_tokens: 100
messages:
- role: system
content: "You summarize incident analysis in 1-2 sentences. State the root cause and the most critical action needed. Output ONLY the summary, nothing else. No markdown."
- role: user
content: "{{ steps.investigate.results.body.analysis }}"
# 4) Write the generated title and summary back onto the incident.
- name: update-incident
if: "'{{ steps.investigate.results.status_code }}' == '200'"
provider:
type: http
with:
url: "http://keep-backend:8080/incidents/{{ incident.id }}"
method: PUT
headers:
x-api-key: "{{ secret.keep_api_key }}"
Content-Type: application/json
body:
user_generated_name: "{{ steps.generate-title.results.body.choices.0.message.content }}"
user_summary: "{{ steps.generate-summary.results.body.choices.0.message.content }}"
# 5) Attach the full Holmes analysis as a comment for anyone who wants the details.
- name: add-comment
if: "'{{ steps.investigate.results.status_code }}' == '200'"
provider:
type: http
with:
url: "http://keep-backend:8080/incidents/{{ incident.id }}/comment"
method: POST
headers:
x-api-key: "{{ secret.keep_api_key }}"
Content-Type: application/json
body:
status: firing
comment: "{{ steps.investigate.results.body.analysis }}"
actions: []
Шаг 1, заголовок. Первым делом надо дать инциденту вменяемое имя. По умолчанию там либо имя первого алерта, либо вообще каша. Поэтому шаг первый: беру все алерты инцидента, скармливаю дешёвой модели и прошу выжать из этого короткий заголовок в два-три слова — «Диск кончается», «Нода легла», что-то такое. Дёшево, быстро, и в ленте инцидентов сразу видно, что горит.
Шаг 2, собственно расследование. Шаг второй стучится в Holmes и говорит: вот инцидент, вот его алерты, разберись. И Holmes уходит работать, лезет в метрики, лезет в логи, сопоставляет, думает. Это самый долгий и самый дорогой шаг, поэтому я навесил на него ретраи: если Holmes споткнулся (а LLM иногда спотыкается), воркфлоу повторит попытку пять раз с паузой в полминуты. Не достучались — ну, значит не судьба, но обычно достукиваемся.
Шаг 3, выжимка. Holmes возвращает простыню текста — подробный анализ с первопричиной и тем, куда копать. Читать это в три часа ночи целиком никто не будет. Поэтому шаг третий снова дёргает дешёвую модель и просит ужать всё в одно-два предложения: вот корень проблемы, вот что делать в первую очередь. Этот шаг и все следующие срабатывают, только если расследование реально удалось — если Holmes отвалился, ничего не дописываем, чтобы не мусорить.
Шаги 4 и 5, вписываем обратно в инцидент. Осталось вернуть всё это в Keep. Шаг четвёртый вписывает в инцидент свежий заголовок и короткую выжимку — то, что инженер видит первым делом. Шаг пятый кладёт полный анализ Holmes отдельным комментарием — для тех, кто захочет деталей. Всё, инцидент из голого списка алертов превратился в нормально оформленную карточку: понятное имя, суть в двух строчках, развёрнутый разбор под катом. И ни одного человека в процессе.
Две модели. Заметили, да? В воркфлоу две разные модели. Тяжёлое расследование тянет одна — нормальная, способная думать. А мелочёвку вроде заголовка и выжимки — другая, подешевле. Незачем гонять дорогую модель ради двух слов в заголовке. Это и есть весь секрет дешевизны: платишь за умную голову только там, где реально надо думать, а на рутину ставишь что попроще.
Здесь стоит сказать пару слов о том, где вообще живут эти модели и как они выбираются. Holmes, воркфлоу и чат сами по себе не знают, с кем разговаривают — они просто стучатся в OpenAI-совместимый эндпоинт. А что стоит за этим эндпоинтом — решает шлюз. Я поставил LiteLLM: одна точка, за которой прячется выбор модели, реальные ключи и учёт расхода. Удобно тем, что сменить модель можно в одном месте, не передеплоивая Holmes и Keep.
Holmes ─┐
workflow ─┼──▶ LLM gateway (LiteLLM) ──▶ модель
chat ─┘ одна точка, (своя / официальный API)
прячет модель и ключ
А вот что ставить за шлюз — это уже развилка, и я пробовал разное. Своя локальная модель (Ollama, vLLM и подобное) — честно, приватно и бесплатно, но нужно железо и качество пониже топа. Официальный API облачного провайдера — честно и качественно, но платно, и данные уходят наружу. И есть третий путь: инструменты вроде cli-proxy-api, которые выставляют твою личную подписку (тот же Claude Code) как обычный OpenAI API. Скажем прямо — по соотношению «цена/качество» это лучшее, что я пробовал: почти даром и умная модель.
Но честно и до конца: это серая зона. Подписка продаётся не под это, и гонять через неё прод — значит однажды получить по шапке от вендора. А cli-proxy-api я упоминаю потому, что раз уж делюсь инструментами — делюсь всеми. Сами решайте, рисковать или нет. Я бы не рисковал.
Расследование — это вход. Но кто закрывает инциденты, когда алерты протухли? Если этого не делать, дашборд зарастает «зависшими» инцидентами, у которых давно ничего не горит. Поэтому раз в полчаса крутится простой CronJob: проходит по активным инцидентам, и если у инцидента ноль горящих алертов — переводит его в resolved. Так замыкается полный цикл: алерты коррелируются в инцидент → агент сам его расследует → когда всё потухло, система сама его закрывает. Человек подключается только если надо реально чинить. Вероятно, это решается каким-то воркфлоу в KeepHQ, но мне было лень разбираться, а cronjob делает своё дело.
apiVersion: batch/v1
kind: CronJob
metadata:
name: keep-resolve-stale-incidents
spec:
schedule: "*/30 * * * *"
jobTemplate:
spec:
template:
spec:
restartPolicy: Never
containers:
- name: resolver
image: curlimages/curl:8.5.0
command: ["sh", "-c"]
args:
- |
API="http://keep-backend:8080"
# пройтись по активным инцидентам и закрыть те, где не горит ни один алерт
curl -s "$API/incidents?candidate=false&limit=100" \
| grep -o '"id":"[^"]*"' | sed 's/"id":"//;s/"//' \
| while read INC; do
FIRING=$(curl -s "$API/incidents/$INC/alerts" | grep -o '"status":"firing"' | wc -l)
if [ "$FIRING" -eq 0 ]; then
curl -s -X POST "$API/incidents/$INC/status" \
-H "Content-Type: application/json" \
-d '{"status":"resolved"}'
fi
done
Каков итог? Вместо стены алертов я получил страничку с инцидентами, где алерты собраны сразу в один понятный скоуп, который к тому же уже более-менее неплохо описан: с человеческим заголовком, выжимкой первопричины и развёрнутым разбором от агента. И всё это без единого клика человека — от прилетевшего алерта до оформленного инцидента с расследованием. А инженер подключается уже не для того, чтобы понять, что вообще произошло, а чтобы это починить.
Ссылки
Раз уж делюсь — то всем, что использовал по дороге. Собирайте свой стек.
Основа:
- KeepHQ — платформа алертов и инцидентов (сайт)
- HolmesGPT — AI-агент для расследования инцидентов
- Robusta — те, кто делает HolmesGPT (сайт)
Данные и мониторинг:
- VictoriaMetrics — метрики
- VictoriaLogs — логи
- mcp-victoriametrics — MCP-сервер к метрикам
- mcp-victorialogs — MCP-сервер к логам
- VictoriaMetrics/skills — те самые методички/ранбуки
- Model Context Protocol — что такое MCP вообще
- CEL (Common Expression Language) — язык фильтров в правилах корреляции Keep
LLM и шлюзы:
- LiteLLM — шлюз перед моделями
- Ollama — локальные модели (сайт)
- vLLM — self-hosted инференс
- CLIProxyAPI — тот самый серый путь: подписка как OpenAI API. Помним про последствия.
Доступ:
- oauth2-proxy — SSO-обвязка перед Keep